Mastering Model Optimization with Olive: Quantizing and Fine-Tuning Phi-3.5
Optimizing AI models can be a complex task, but tools like Microsoft Olive simplify the process by providing a unified framework. Olive stands out due to its comprehensive capabilities, including automation of optimization tasks, seamless integration with Hugging Face and Azure AI, and support for multiple hardware accelerators like CPUs, GPUs, and NPUs. This makes it an invaluable tool for simplifying deployment-ready model preparation.
In this post, I’ll demonstrate how to use Olive for quantization, fine-tuning, and exporting models, specifically using the Phi-3.5 model as an example. While the focus is on Phi-3.5, the same approach can be applied to fine-tune and optimize other models.
What is Olive?
Olive is a state-of-the-art model optimization toolkit and CLI that simplifies the process of preparing models for deployment using the ONNX runtime. It takes a PyTorch or Hugging Face model as input and outputs an optimized ONNX model, ready to run on target devices like CPUs, GPUs, or NPUs provided by vendors such as Qualcomm, AMD, Nvidia, or Intel.
Benefits of Olive:
- Streamlined Optimization: Automatically optimizes models for specific deployment targets and precision levels, reducing the need for trial-and-error experimentation.
- Comprehensive Techniques: Includes built-in optimization methods for quantization, compression, graph optimization, and fine-tuning.
- Ease of Use: Provides an intuitive CLI for tasks like
quantize,auto-opt, andfinetune. We will focus on those commands in this post, but full advanced workflows can also be orchestrated with YAML/JSON. - Deployment-Ready: Built-in features for model packaging and deployment.
- Integration: Supports Hugging Face and Azure AI platforms.
- Productivity: Built-in caching mechanism improves efficiency.
Pre-req: Installing Olive
To get started, install Olive and its dependencies. Use the following commands:
1
2
3
4
pip install olive-ai[auto-opt,finetune,cpu]
pip install transformers==4.44.2
pip install autoawq
pip install auto-gptq
If you plan to run Olive on a GPU, replace
cpuwithgpuin the Olive installation command to ensure GPU dependencies are installed. Note, fine-tuning requires a GPU to achieve efficient training speeds.
Steps
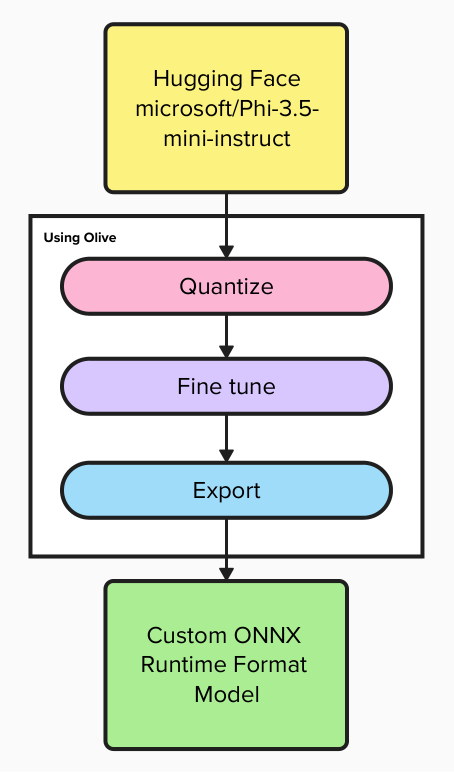
Step 1: Quantizing a Model
Quantization is the process of reducing the precision of model parameters, which decreases model size and increases inference speed while retaining comparable accuracy. According to this Olive blog post, it is recommended to quantize a model before fine-tuning to optimize for performance and resource efficiency.
Here’s a basic example for performing quantization:
1
2
3
4
5
olive quantize \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--algorithm awq \
--precision int4 \
--output_path ./models/quantized_phi-3.5
Explanation of Parameters:
--model_name_or_path: Specifies the path to the pre-trained model (e.g. a Hugging Face model likemicrosoft/Phi-3.5-mini-instructor a path to a local model).--algorithm: Sets the quantization algorithm (e.g.awq,quarotetc).--precision: Sets the precision (e.g.int4,fp8etc).--output_path: Directory to save the quantized model.
A full list of parameters can be found in the Olive API docs.
Step 2: Fine-Tuning a Model
Fine-tuning customizes a pre-trained model to perform better on specific datasets.
Importance of Input Data
However, the success of fine-tuning heavily relies on the quality and consistency of your dataset. High-quality datasets with sufficient and diverse samples are essential for ensuring that the fine-tuned model performs well. Poor quality or inconsistent datasets can lead to suboptimal results.
To ensure dataset quality:
- Sufficiency: Your dataset should contain enough examples to cover the scope of the tasks the model will perform.
- Consistency: Format and label your data consistently to avoid confusion during training.
- Relevance: Ensure the data is directly related to the tasks the model is expected to handle.
The input data should be in a structured format, such as JSONL, where each line represents one sample. Here’s an example:
{"system_prompt": "Translate English to French.", "prompt": "Hello, how are you?", "ground_truth": "Bonjour comment allez-vous?"}
{"system_prompt": "Summarize the following text:", "prompt": "The quick brown fox jumps over the lazy dog.", "ground_truth": "Fox jumps over dog."}
Each line represents a training sample with fields for the system’s instruction (system_prompt), user input (prompt), and expected output (ground_truth).
Fine-Tuning Script
Here’s the script for fine-tuning:
1
2
3
4
5
6
7
8
9
10
11
olive finetune \
--model_name_or_path ./models/quantized_phi-3.5 \
--data_name data/ \
--train_split "train[:80%]" \
--eval_split "train[20%:]" \
--text_template "<|system|>\n{system_prompt}<|end|>\n<|user|>\n{prompt}<|end|>\n<|assistant|>\n{ground_truth}<|end|>" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--report_to azure_ml \
--output_path ./models/fine_tuned_phi-3.5
Explanation of Parameters:
--model_name_or_path: The path to the quantized model or a Hugging Face/local model to fine-tune.--data_name: Specifies the directory for the training data.--train_split: Percentage of the data used for training.--eval_split: Percentage of the data used for evaluation.--text_template: Template for formatting training data. Note how the template references the fields defined in the example dataset. This template will be different for other types of models compared to Phi-3.5.--per_device_train_batch_size: Batch size for training per device.--per_device_eval_batch_size: Batch size for evaluation per device.--max_steps: Maximum number of training steps.--report_to: Specifies the reporting system (e.g.,azure_ml). When set toazure_mland running within Azure ML, this reports metrics which are then displayed as graphs.--output_path: Path to save the fine-tuned model.
A full list of parameters can be found in the Olive API docs.
Step 3: Exporting a Model
Exporting prepares the model for deployment. Olive-optimized models are particularly beneficial in deployment scenarios that require high efficiency and compatibility, such as edge computing or mobile devices
Note that the latest release of Olive does not automatically download the required modeling and configuration files. You must download these files manually. This issue is resolved in the main branch of Olive but is not yet released. You can retrieve the required files by running:
1
2
curl https://huggingface.co/microsoft/Phi-3.5-mini-instruct/raw/main/modeling_phi3.py -o "./models/fine_tuned_phi-3.5/model/modeling_phi3.py"
curl https://huggingface.co/microsoft/Phi-3.5-mini-instruct/raw/main/configuration_phi3.py -o "./models/fine_tuned_phi-3.5/model/configuration_phi3.py"
Here’s the script for exporting:
1
2
3
4
5
6
7
8
9
olive auto-opt \
--model_name_or_path ./models/fine_tuned_phi-3.5/model \
--adapter_path ./models/fine_tuned_phi-3.5/adapter \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--use_ort_genai \
--output_path ./models/exported_phi-3.5
Explanation of Parameters:
--model_name_or_path: Path to the model to be exported.--adapter_path: Specifies the adapter used for optimization.--device: Specifies the target device (e.g.,cpu,npuorgpu).--provider: Execution provider for optimization (e.g.,CPUExecutionProvider,QNNExecutionProvider,CUDAExecutionProvideretc).--precision: Sets the precision level (e.g.,int4,fp8etc).
A full list of parameters can be found in the Olive API docs.
Conclusion
Microsoft Olive simplifies model optimization for deployment with its powerful CLI and integrated tools. Whether you’re quantizing, fine-tuning, or exporting, Olive provides the flexibility to adapt to your specific needs. To achieve the best results, ensure you provide high-quality datasets during fine-tuning and experiment with different parameters in the Olive commands to find the optimal configuration for your use case. The journey to model optimization is iterative, and Olive makes it both accessible and efficient.